整个项目包中的路径不能有中文,不能有中文,不能有中文,文件位置task_menu/。
数据格式如下

前期不会操作的建议一个一个来熟练之后批量操作。前期不会操作的建议一个一个来熟练之后批量操作。前期不会操作的建议一个一个来熟练之后批量操作。
系统环境配置整个项目包中的路径不能有中文,不能有中文,不能有中文,文件位置config下。
这里设置用户名和密码是购买脚本后管理员发放的,直接填写替换掉对应你的用户名和你的密码部分的内容就好。
UserData={'username':'你的用户名',填写你的密码}字幕识别配置,模型选择根据自己的机器显存选择。
24G显存建议选择large-v2。
16G显存建议选择large-v1。
8G显存建议选择large。
8G以下自己想办法吧。
whisper路径绘画关键词前缀PROMPT="bestquality,masterpiece,illustration,anextremelydelicateandbeautiful,extremelydetailed,CG,unity,8kwallpaper,"图片宽度sd_image_height=1080生成图片采样方法,这里不会改就别动
video_format='w'这个没法解释自己试一下吧
微软TTS文本转语音,需要自己有一张VISA,不明白是啥自行百度,微软申请账号需要。
微软TTS文本转语音,这里必须选择eastus服务器,申请好API之后填写即可。
申请地址"你的API"必须选择eastus服务器
如果自己没有办法申请自己的API,可有偿提供封装API,这里就无视即可。
微软语音选择,这部分代码不要动。
语气style_dict={'兴奋':'advertisement_upbeat','高音调':'affectionate','厌恶':'angry','热情':'customerservice','冷静':'calm','轻松':'chat','愉快':'cheerful','忧郁':'depressed','轻蔑':'disgruntled','纪录片':'documentary-narration','犹豫':'embarrassed','关切':'empathetic','钦佩':'envious','希望':'excited','紧张':'fearful','愉悦':'frily','温和':'hopeful','优美':'lyrical','朗读':'narration-professional','阅读':'narration-relaxed','新闻':'newscast','通用':'newscast-casual','权威':'newscast-formal','快节奏':'poetry-reading','悲伤':'sad','严肃':'serious','高声':'shouting','赛事':'sports_commentary','精彩':'sports_commentary_excited','柔和':'whispering','疯狂':'terrified','无情':'unfrily'}role_dict={'女孩':'Girl','男孩':'Boy','年轻的成年女性':'YoungAdultFemale','年轻的成年男性':'YoungAdultMale','年长的成年女性':'OlderAdultFemale','年长的成年男性':'OlderAdultMale','年老女性':'SeniorFemale','年老男性':'SeniorMale'}ger_dict={'男':'Male','女':'Female'}上面的格式是这样的,大括号{}中以每个,断开来看,:前面是你要复制的信息,后面是对应这个信息的解释。
例如想使用云希的声音在name_dict中复制

到下面如何修改在这里这里,其他的依次类推,目前支持自定义修改,但是有的声音配置可能不支持,比如云希不会有女人声音这样,具体慢慢尝试或者百度即可。
发音人声音name=name_dict["Yunxi"]性别ger=ger_dict["男"]audio_rate='1.4'剪映需要的完整路径full_path="H:\\NovelAI\\UserEdition\\sell_NovelAI_txt2video"
这个配置不对,剪映的配置文件会出错。
这部分内容容易被和谐自己看图吧。

执行该脚本是将task_menu/下的未完成的文章进行断句操作。
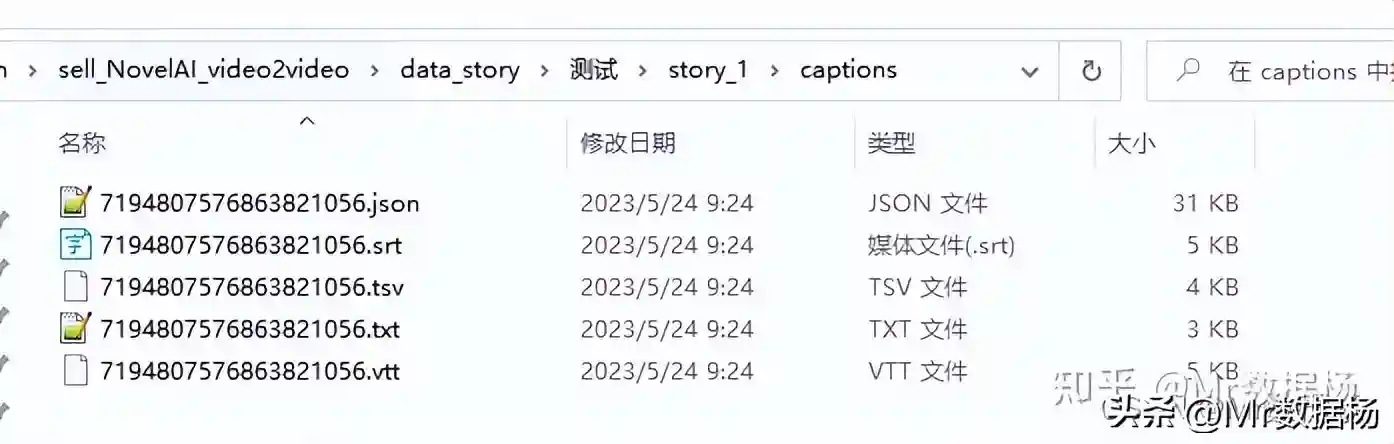
会在data_story/下生成你表格中定义的collection_name和en_name文件夹,在该项目下会自动生成一个captions文件夹。
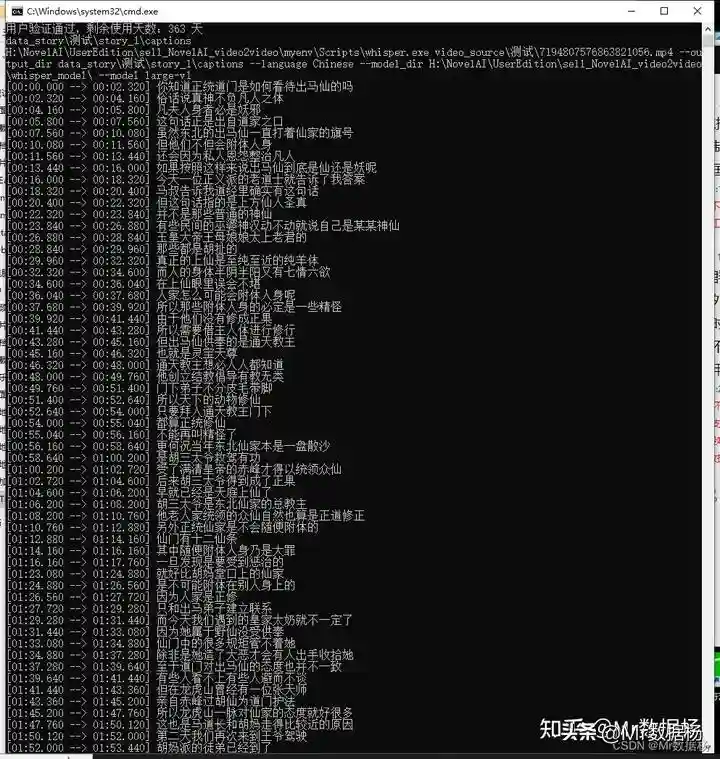
这里是通过whisper进行字幕提取操作。
会生成如下文件。
新建一个文本文件,文件名为new_+video_id+.txt。
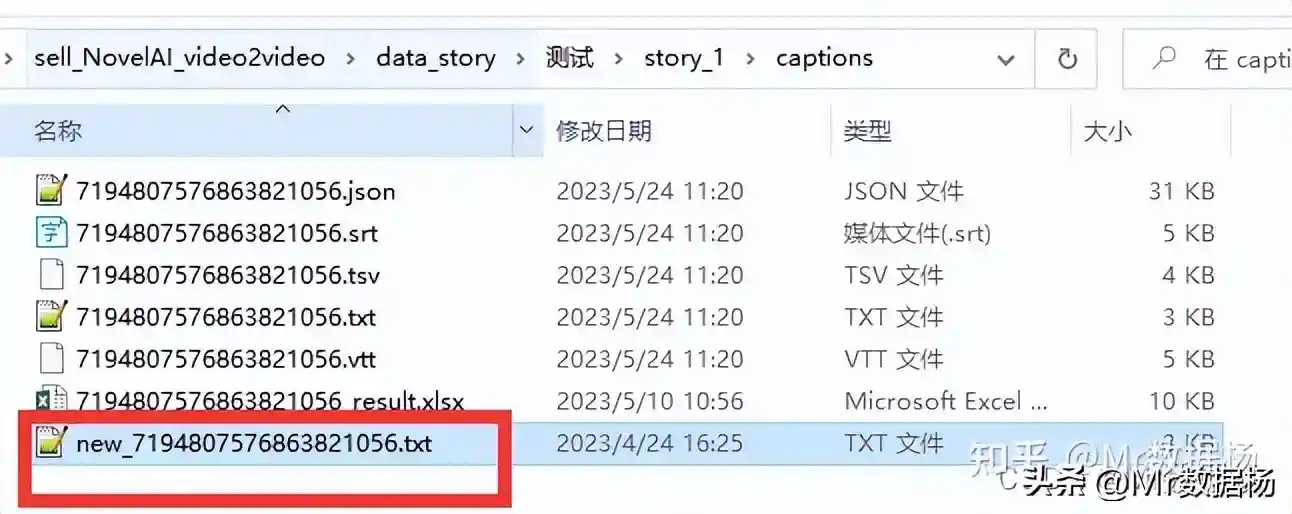
会在data_story/下生成你表格中定义的collection_name和en_name文件夹,在该项目下会自动生成一个captions文件夹下有一个excel表格。
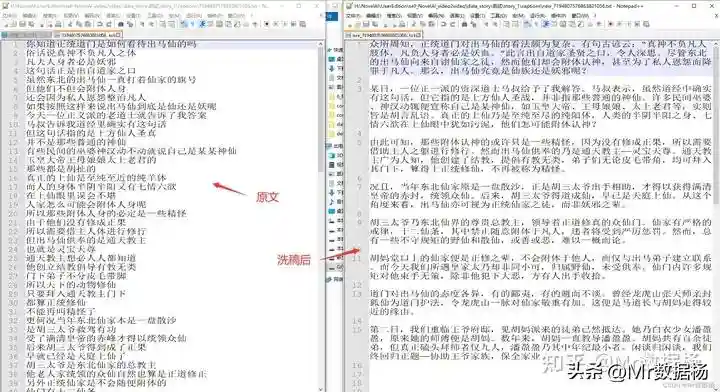
这个是需要处理的工程文件目录,不要动这个表格。
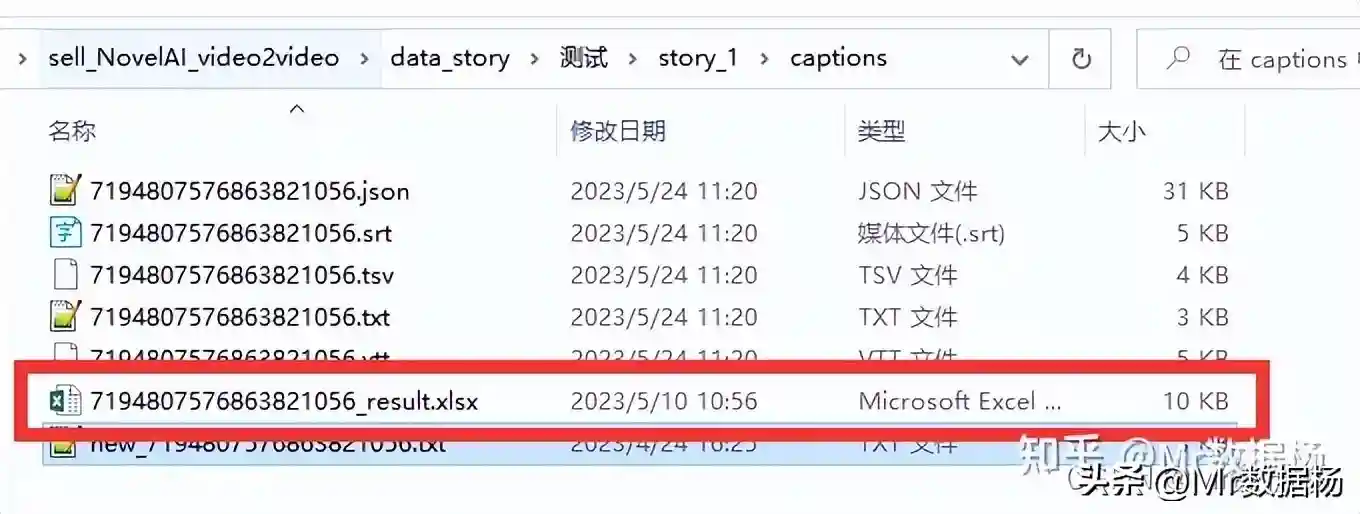
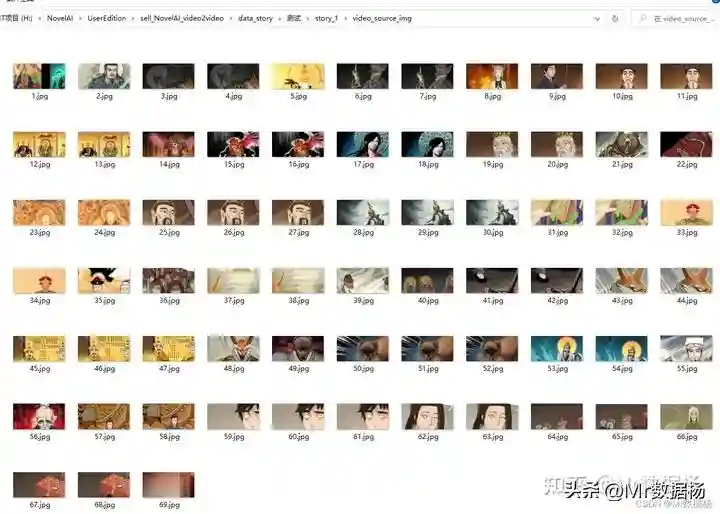
会在data_story/下生成你表格中定义的collection_name和en_name文件夹,在该项目下会自动生成一个video_source_img文件夹下对画面进行截图然后通过SD重绘。
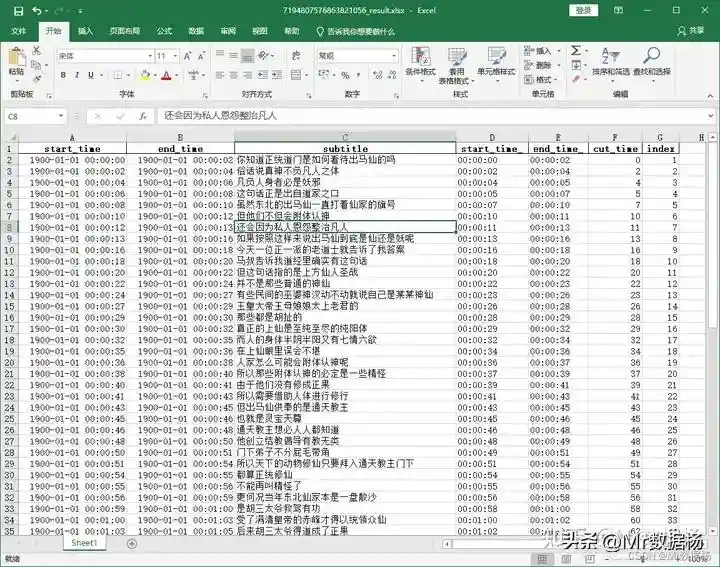
这里需要自己调试截取的像素点,在中配置。
左上角像素点x2,y2=630,1280#右下角像素点【通用】step5_使用TTS生成语音.bat
需要在配置文件中使用你的微软文字转语音API,使用微软的API生成语音文件。
会在你生成项目也就是故事的文件夹生成2个目录audio_wav,each_audio_wav,确保里面的音频文件都有声音即可,在生成界面会看到返回结果为200,即可。
在文件夹下会生成对应的音频文件,脚本设置的已经生成的会跳过,如果音频文件没有声音请删除重新执行脚本。
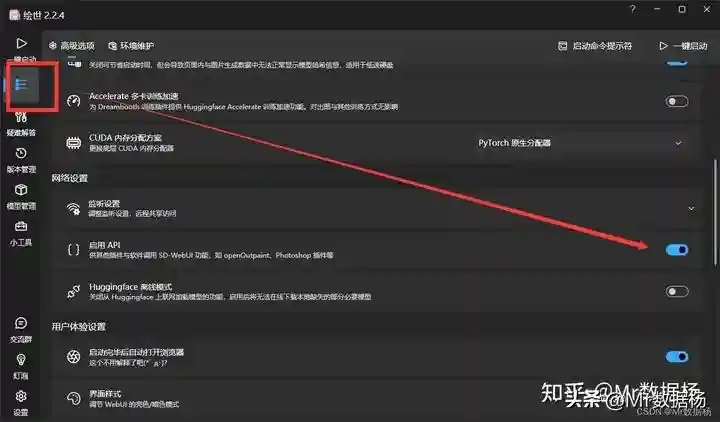
需要提前打开StableDiffusion环境,并开启API模型。启动命令行显示这样就表示可以了。
在网页上选择你需要的模型,之后页面就可以关掉了。

启动脚本即可,会自动的进行绘画,基于前面API生成的关键词。生成图片在data_story/下生成你表格中定义的collection_name和en_name文件夹下生成video_source_sd_img图片文件。

执行该脚本会在data_story/下生成你表格中定义的collection和en_name文件夹下生成result生成一个剪映的配置文件draft_,这个文件仍到你剪映的项目中打开就会看到图文适配音频的工程时间轴,方便后期二次加工。
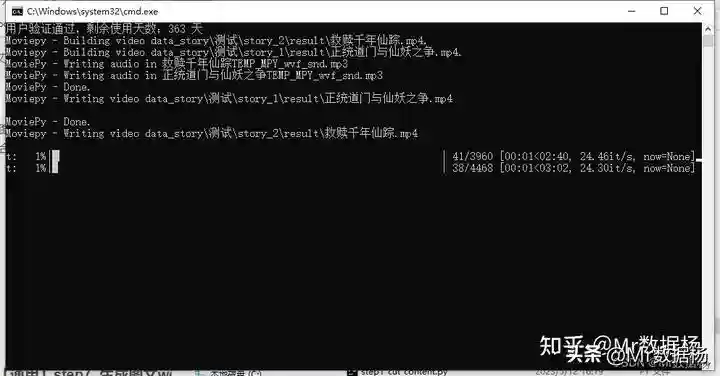
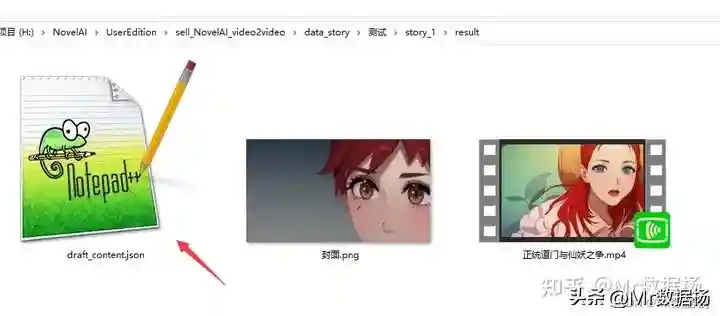
执行该脚本会在data_story/下生成你表格中定义的type和en_name文件夹下生成result生成一个剪映的配置文件AE_,这个文件仍到你剪映的项目中打开就会看到图文适配音频的工程时间轴,方便后期二次加工。
这里的文件路径不要有中文,建议在第一步切分的时候设置type中不要有中文
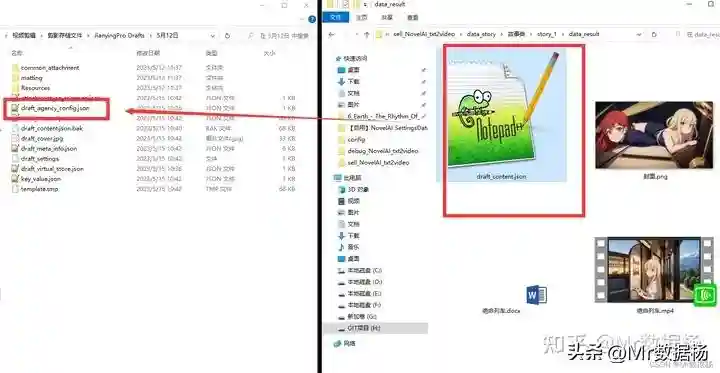
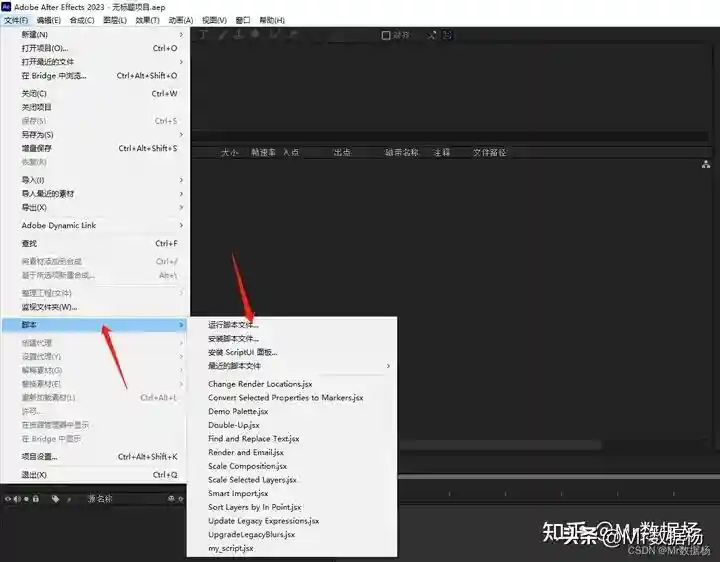
打开AE直接在按照下图,打开脚本。

然后在编辑主轴中会显示这样。